本次美国代写是Python强化学习的一个assignment
Introduction
In this project, you will implement value iteration and Q-learning. You will test your agents first on Gridworld (from class), then apply them to a simulated robot controller (Crawler) and Pacman.
Like Project 1, this project includes an autograder for you to grade your solutions on your machine. This can be run on all questions with the command:
python autograder.py
It can be run for one particular question, such as q2, by:
python autograder.py -q q2
It can be run for one particular test by commands of the form:
python autograder.py -t test_cases/q2/1-bridge-grid
| Files you’ll edit: | |
valueIterationAgents.py |
A value iteration agent for solving known MDPs. |
qlearningAgents.py |
Q-learning agents for Gridworld, Crawler and Pacman. |
analysis.py |
A file to put your answers to questions given in the project. |
| Files you should read but NOT edit: | |
mdp.py |
Defines methods on general MDPs. |
learningAgents.py |
Defines the base classes ValueEstimationAgent and QLearningAgent, which your agents will extend. |
util.py |
Utilities, including util.Counter, which is particularly useful for Q-learners. |
gridworld.py |
The Gridworld implementation. |
featureExtractors.py |
Classes for extracting features on (state,action) pairs. Used for the approximate Q-learning agent (in qlearningAgents.py). |
| Files you can ignore: | |
environment.py |
Abstract class for general reinforcement learning environments. Used by gridworld.py. |
graphicsGridworldDisplay.py |
Gridworld graphical display. |
graphicsUtils.py |
Graphics utilities. |
textGridworldDisplay.py |
Plug-in for the Gridworld text interface. |
crawler.py |
The crawler code and test harness. You will run this but not edit it. |
graphicsCrawlerDisplay.py |
GUI for the crawler robot. |
autograder.py |
Project autograder |
testParser.py |
Parses autograder test and solution files |
testClasses.py |
General autograding test classes |
test_cases/ |
Directory containing the test cases for each question |
reinforcementTestClasses.py |
Project 2 specific autograding test classes |
Files to Edit and Submit: You will fill in portions of valueIterationAgents.py, qlearningAgents.py, and analysis.py during the assignment. You should submit these files with your code and comments. Please do not change the other files in this distribution or submit any of our original files other than these files.
Evaluation: Your code will be autograded for technical correctness. Please do not change the names of any provided functions or classes within the code, or you will wreak havoc on the autograder.
Academic Dishonesty: We will be checking your code against other submissions in the class for logical redundancy. If you copy someone else’s code and submit it with minor changes, we will know. These cheat detectors are quite hard to fool, so please don’t try. We trust you all to submit your own work only; please don’t let us down. If you do, we will pursue the strongest consequences available to us.
Getting Help: You are not alone! If you find yourself stuck on something, contact the course staff for help. Office hours and Piazza are there for your support; please use them. If you can’t make our office hours, let us know and we will schedule more. We want these projects to be rewarding and instructional, not frustrating and demoralizing. But, we don’t know when or how to help unless you ask.
MDPs
To get started, run Gridworld in manual control mode, which uses the arrow keys:
python gridworld.py -m
You will see the two-exit layout from class. The blue dot is the agent. Note that when you press up, the agent only actually moves north 80% of the time. Such is the life of a Gridworld agent!
You can control many aspects of the simulation. A full list of options is available by running:
python gridworld.py -h
The default agent moves randomly
python gridworld.py -g MazeGrid
You should see the random agent bounce around the grid until it happens upon an exit. Not the finest hour for an AI agent.
Note: The Gridworld MDP is such that you first must enter a pre-terminal state (the double boxes shown in the GUI) and then take the special ‘exit’ action before the episode actually ends (in the true terminal state called TERMINAL_STATE, which is not shown in the GUI). If you run an episode manually, your total return may be less than you expected, due to the discount rate (-d to change; 0.9 by default).
Look at the console output that accompanies the graphical output (or use -t for all text). You will be told about each transition the agent experiences (to turn this off, use -q).
As in Pacman, positions are represented by (x,y) Cartesian coordinates and any arrays are indexed by [x][y], with 'north' being the direction of increasing y, etc. By default, most transitions will receive a reward of zero, though you can change this with the living reward option (-r).
Question 1 (6 points): Value Iteration
Write a value iteration agent in ValueIterationAgent, which has been partially specified for you in valueIterationAgents.py. Your value iteration agent is an offline planner, not a reinforcement learning agent, and so the relevant training option is the number of iterations of value iteration it should run (option -i) in its initial planning phase. ValueIterationAgent takes an MDP on construction and runs value iteration for the specified number of iterations before the constructor returns.
Value iteration computes k-step estimates of the optimal values, Vk. In addition to running value iteration, implement the following methods for ValueIterationAgent using Vk.
computeActionFromValues(state)computes the best action according to the value function given byself.values.computeQValueFromValues(state, action)returns the Q-value of the (state, action) pair given by the value function given byself.values.
These quantities are all displayed in the GUI: values are numbers in squares, Q-values are numbers in square quarters, and policies are arrows out from each square.
Important: Use the “batch” version of value iteration where each vector Vk is computed from a fixed vector Vk-1 (like in lecture), not the “online” version where one single weight vector is updated in place. This means that when a state’s value is updated in iteration k based on the values of its successor states, the successor state values used in the value update computation should be those from iteration k-1 (even if some of the successor states had already been updated in iteration k). The difference is discussed in Sutton & Barto in the 6th paragraph of chapter 4.1.
Note: A policy synthesized from values of depth k (which reflect the next k rewards) will actually reflect the next k+1 rewards (i.e. you return πk+1πk+1). Similarly, the Q-values will also reflect one more reward than the values (i.e. you return Qk+1).
You should return the synthesized policy πk+1πk+1.
Hint: Use the util.Counter class in util.py, which is a dictionary with a default value of zero. Methods such as totalCount should simplify your code. However, be careful with argMax: the actual argmax you want may be a key not in the counter!
Note: Make sure to handle the case when a state has no available actions in an MDP (think about what this means for future rewards).
To test your implementation, run the autograder:
python autograder.py -q q1
The following command loads your ValueIterationAgent, which will compute a policy and execute it 10 times. Press a key to cycle through values, Q-values, and the simulation. You should find that the value of the start state (V(start), which you can read off of the GUI) and the empirical resulting average reward (printed after the 10 rounds of execution finish) are quite close.
python gridworld.py -a value -i 100 -k 10
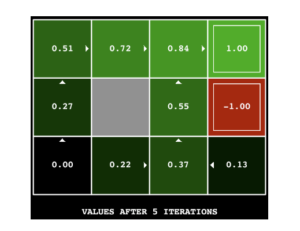
Hint: On the default BookGrid, running value iteration for 5 iterations should give you this output:
python gridworld.py -a value -i 5