本次美国代写是一个电路相关的Problem Set
1. For each of the instructions below, highlight all wires in the MIPS datapath whose value does not
matter during the instruction’s execution. A wire’s value does not matter if it could be cut and the
instruction would still work correctly.
a. addi $a0, $a0, 1
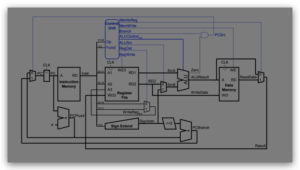
b. lw $t1, 8($s0)
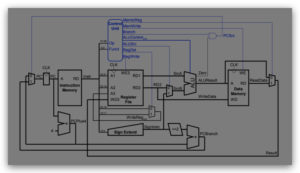
c. beq $t1, $t0, somelabel
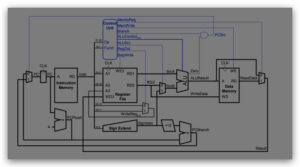
2. Assuming the single cycle datapath from lecture as a baseline design, calculate the speedup under
the scenarios listed below.
a. If the ALU were 4x faster (i.e., if its delay were divided by 4) what would the speedup
be?
b. If the MUX delay were reduced to 5ps, what would the speedup be?
3. Imagine if the MIPS ISA were changed not to use base + offset addressing. Instead, all pointers
must be explicitly calculated by other instructions. So, for example the actual instruction
lw $dst, offset($base)
would become
addiu $address, $base, offset
lw $dst $address
Assume that the $address register identifier is encoded in the instruction word in the same place
as the $base was in the original. Show how the single cycle datapath and control could be
modified to implement this change. Take care that all instructions other than lw and sw operate
as normal.
4. Examine the array sum function below. The first argument is a pointer to an array of integers and
the second argument is the length of the array. Note how each instruction is individually labelled
for easy identification.
add1: add $v0, $0, $0
beq1: beq $a1, $0, jr1
addi1: addiu $a1, $a1, -1
lw1: lw $t0, 0($a0)
add2: add $v0, $v0, $t0
addi2: addiu $a0, $a0, 4
beq2: beq $0, $0, beq1
jr1: jr $ra
a. How many instructions will be executed when this function is invoked on an array N
integers?
b. Assuming a five stage pipeline with early branch resolution and data forwarding from
W-X, M-X and M-D, indicate where and how many bubbles will occur (e.g., 1 bubble
between lw1 and add2).


