这是一篇来自加拿大的作业主要关于一个数据分析和机器学习基础的限时测试机器学习代写
2. [2] We have that
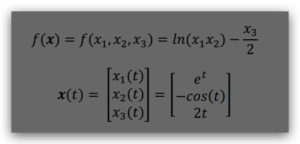
Calculate the gradient 𝑑𝑓/𝑑𝑡. Show all your calculations.
3. [3] Binary classification Model A achieves a top F1 score of F1A and an area under the ROC curve
(AUC) of AUCA, whereas binary classification Model B achieves a top F1 score of F1B and an AUC
of AUCB, on the same dataset. If AUCA > AUCB., is it implied that F1A > F1B? Why?
4. [3] StandardScaler (in sklearn) is often used in linear regression models.
a. What does StandardScaler do?
b. Is it best practice to apply StandardScaler before or after splitting data into training and
testing groups? Why?
c. Typically, is it useful to apply StandardScaler on targets, feature data, or both?
5. [3] Sam applies linear regression to data that has a single feature, x. A first model, Model A,
makes predictions y using only a bias (𝑤0) and a weighted feature (𝑤1𝑥), i.e. 𝑦 = 𝑤0 + 𝑤1𝑥.
Unsatisfied, Sam then creates new features that are the x feature squared and cubed, yielding
the model 𝑦 = 𝑤0 + 𝑤1𝑥 + 𝑤2𝑥22 + 𝑤3𝑥33 (Model B), which still isn’t a great fit.
a. What minimum degree polynomial is needed to fit the data reasonably well? Why?
[hint: count turning points (extremums) of polynomial]
b. Can you conceive of an alternate feature mapping scheme, where a single additional
feature is added to Model A, that would fit the data well? Explain your reasoning.


