这是一篇美国的E20缓存模拟器代码代写
1 Introduction
This project represents a substantive programming exercise. Like all work for this class, it is to be completed
individually: any form of collaboration is prohibited, as detailed in the syllabus. This project is considered a take-home exam.
Before even reading this assignment, please read the E20 manual thoroughly. Read the provided E20 assembly language examples.
If you have not completed your E20 simulator, please do so before beginning this assignment.
2 Assignment: Cache simulator
Your task is to write an E20 cache simulator: a program that will monitor the effects that an E20 program’s execution has on a memory cache. This project will build on your E20 simulator, by adding a simulated cache subsystem.
Your simulator will be given a cache configuration, specifying the number and type of caches. Your simulator will support up to two caches. Therefore, your program should be prepared to accept a cache configuration with either just an L1 cache, or both an L1 and an L2 cache.
Each cache will be defined by three parameters, given as integers: the size of the cache, the cache’s associativity, and the cache’s blocksize (measured in number of cells):
cache size
The total size of the cache, excluding metadata.The value is expressed as a multiple of the size of a memory cell. This will be a positive integer power of 2 that will be at least the product of the associativity and blocksize.
cache associativity
The number of blocks per cache line. This will be an integer in the set {1, 2, 4, 8, 16}. An associativity of 1 indicates a direct-mapped cache. If the product of the associativity and the blocksize is equal to the cache size, and the associativity is greater than 1, then the cache is fully associative.
cache blocksize
The number of memory cells per cache block. This will be an integer in the set {1, 2, 4, 8, 16, 32, 64}.
Your simulator will monitor the effects on the cache or caches while executing an E20 program.The output of your simulator will be a log of all cache hits and cache misses, in chronological order, caused by all executed lw and sw instructions.
- When an sw instruction is executed, the log will be appended with a line indicating so, along with the current value of the program counter, the memory address that was written, and the cache line where the data was cached. The format is as follows:
L1 SW pc: 2 addr: 100 line: 4
If there are two caches, then the write to both affected caches should be logged separately, as follows:
L1 SW pc:2 addr: 100 line:4
L2 SW pc:2 addr: 100 line:0
In the above case, the data was written to both L1 and L2, as dictated by a write-through policy.
- When an lw instruction is executed, the log will be appended with a line indicating so, along with whether the memory read was a hit or a miss, the current value of the program counter, the memory address that was written, and the cache line where the data was cached. The format is as follows, in the case of a miss:
L1 MISS pc:22 addr: 128 line:4
Alternatively, in the case of a hit, you should indicate that there was a hit:
L1 HIT pc:22 addr: 128 line: 4
If there are two caches, then we will consult the L2 cache only when the L1 cache misses. In that case,the access to both affected caches should be logged separately, as follows:
L1 MISS pc: 22 addr: 128 line:4
L2 HIT pc:22 addr: 128 line:0
In the above case, the read was a miss on L1, but hit on L2. Another situation to consider is when the read misses on both caches.
Instructions that do not access memory (such as addi, j, etc) will not be logged.
For the purposes of this project, we assume that instruction fetches bypass the caches, and therefore will not be logged. In a real computer, reading instructions from memory, just like reading data, would be cached.
The initial value of all memory cells and all registers is zero. The initial state of all caches is empty.If both caches are present, the blocksize of L1 will not be larger than the blocksize of L2.
For memory reads, if the desired cell is already in a cache, it will result in a hit. When there are two caches, a memory read will access the L2 cache only when the L1 cache misses. Consider the following diagram describing the logic:
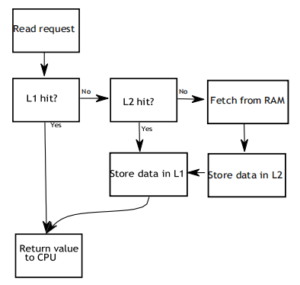
For memory writes, your program will use a write-through with write-allocate policy in all cases. That is, a memory write will simultaneously write the value to all caches, as well as memory. Effectively, writes are handled by the caches as if they were misses.
For associative caches, your program should use the least-recently-used (LRU) replacement policy. This policy is relevant when an associative cache line is full, and a memory access causes a new block to be cached to that line, so we need to evict one of the blocks to make room for it. The block that is to be removed is always the block that has been used least recently. Here, “used” means read (via a cache hit), written (via a cache miss), or written (via a memory write). Therefore, whenever you access a cache, you will need to update bookkeeping to keep track of the order in which blocks have been used.


